Введение
Как правило, построение онтологии требует использования больших ресурсов, а также экспертных знаний в предметной области, и занимает существенный объем времени. Таким образом, автоматизация процесса построения онтологии является актуальной задачей.
Представляется возможным автоматическое построение онтологии по коллекции текстовых документов преимущественно на основе статистических методов анализа текстов на естественном языке. Содержание документов в коллекции непосредственно влияет на качество получаемой онтологии. Если тематически тексты документов слабо связаны, скорее всего, построенная онтология окажется невыразительной, поскольку будет описывать отдельные аспекты различных предметных областей, не создавая при этом общей картины.
Описание системы
На рисунке 1 показана диаграмма верхнего уровня процесса «Генерация онтологии на основе структурированного материала».
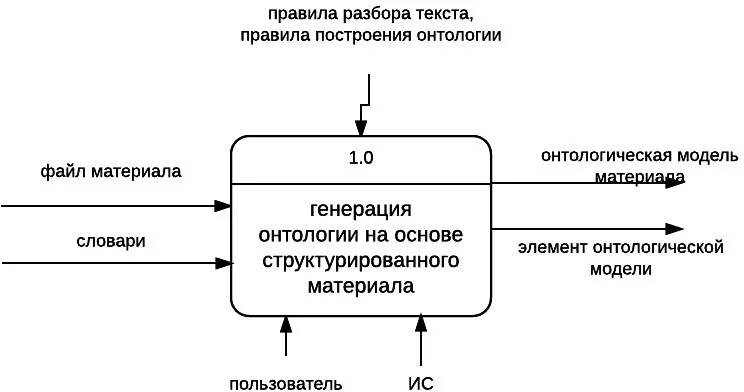
Входной информацией являются файл структурированного учебного материала и словари, которые загружает пользователь ИС. Данная входная информация используется на всех этапах генерации онтологической модели.
Выходной информацией в процессе генерации онтологической модели являются: онтологическая модель материала и описание элементов, входящих в состав онтологической модели.
Исполнителями процесса являются пользователь ИС и информационная система (ИС*).
Управление процессом осуществляется на основании правил разбора текста и правил построения онтологической модели.
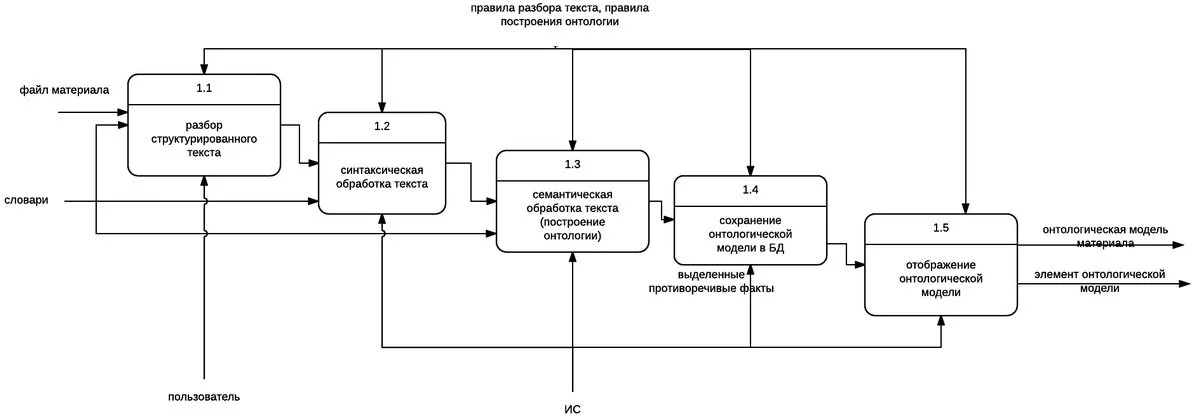
Генерация онтологии на основе структурированного материала осуществляется в пять этапов:
- Разбор структурированного текста» — на данном этапе пользователь выбирает загрузку структурированного текста в систему, после этого система выполняет заполнение внутренних структур программы элементы считанными из файла;
- Синтаксическая обработка текста» — на данном этапе выполняется разбор предложений элементов, выделенных из структурированного текста;
- Семантическая обработка текста (построение онтологии)» — на данном этапе выполняется выделение смысловых единиц текста, образующих элементы онтологической модели, т.е. и выделение вершин модели, также на данном этапе выполняется поиск и расстановка связей вершин;
- Сохранение онтологической модели в БД» — на данном этапе выполняется сохранение полученной модели в БД;
- Отображение онтологической модели» — на данном этапе выполняется вывод полученной онтологической модели в виде графа с выводом информации о каждом элементе онтологической модели.
На рисунке 2 показана детализация процесса «Поиск кратчайшего пути в графе».
Разработанная программно-информационная система для автоматической генерации онтологии на основе структурированного материала предназначена для разбора текстовых документов и построения по результатам разбора онтологической модели курса.
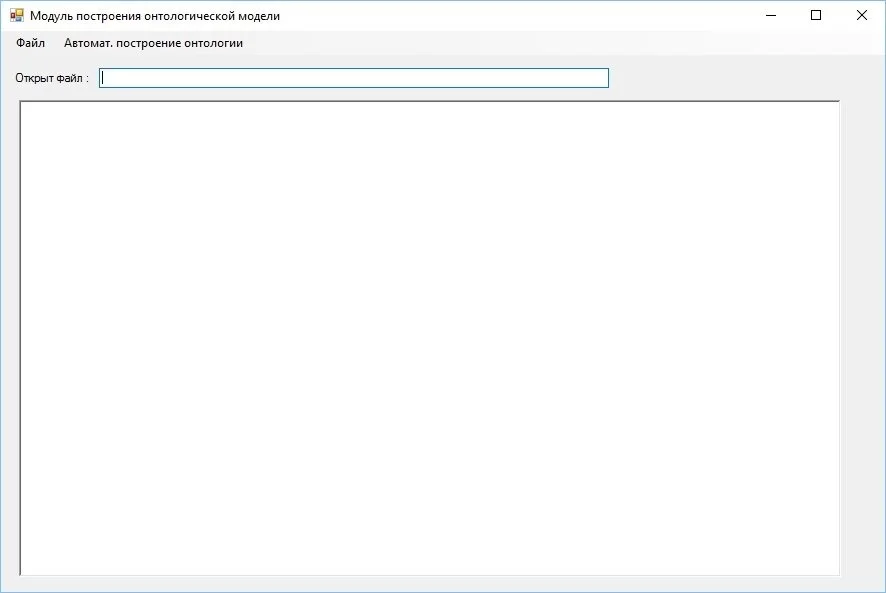
После запуска разработанного приложения открывается основное окно разработанного приложения. Экранная форма основного окна показана на рисунке 3.
Экранная форма диалогового окна "Открытый файл" представлена на рисунке 4.
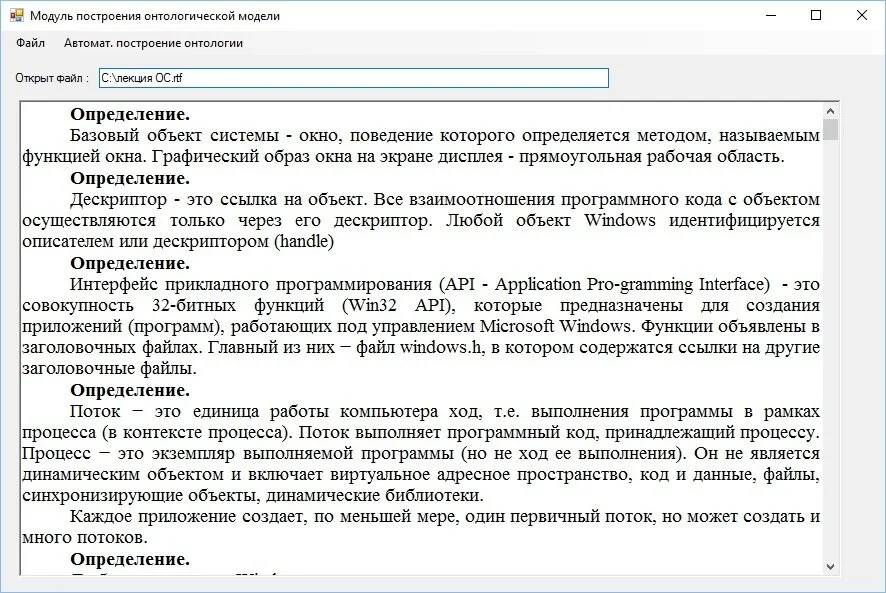
Когда необходимо внести какие-либо изменения в открытый файл формата.RTF это можно сделать используя первое поле вывода текстового файла в основном окне приложения. После внесения изменений необходимо сохранить измененный файл, выбрав пункт "Сохранить в формате RTF" в меню "Файл" основного окна. Появиться стандартное окно операционной системы Windows для сохранения файлов — "Сохранить как". В нем необходимо ввести имя сохраняемого файла. Возможен вариант записи сохраняемого файла взамен уже существующего файла.
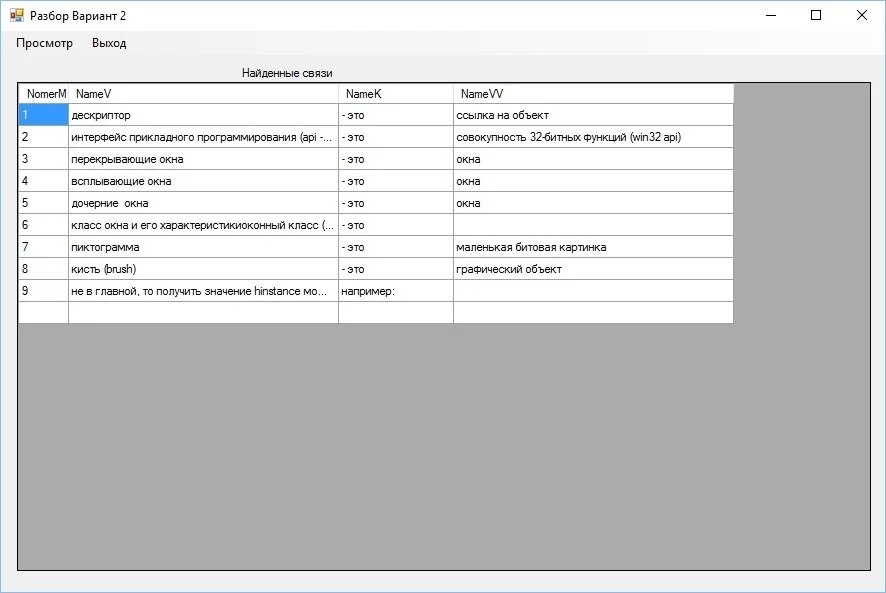
Результаты разбора текстового документа выводятся в экранную форму в виде таблицы. В таблице отражены все, найденные в текстовом документе, ключевые слова и связанные с ними термины. Формат связей формируется основываясь на форму построения предложений в тексте: «определение 1» — «ключевое слово» — «определение 2». Именно по этому требуется предварительная подготовка коллекции текстовых документов согласно введенным правилам.
Экранная форма окна "Результаты разбора текстового документа" показана на рисунке 5.
После окончания анализа и разбора текстового документа переходим к построению онтологической модели этого текстового документа. Для этого выбираем пункт "Отображение" из меню "Вариант 2" основной формы и активируем процесс построения онтологической модели (рисунок 6).
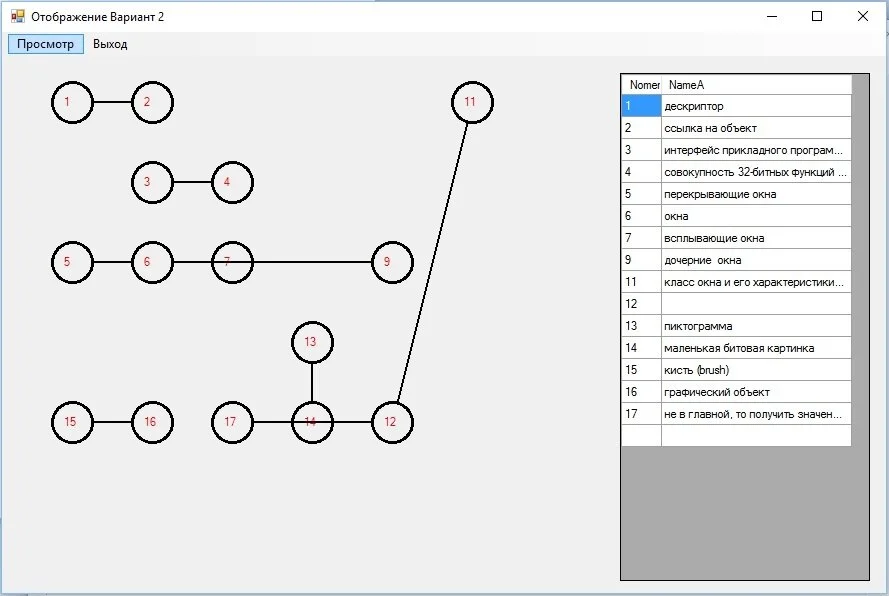
Онтологическая модель, построенная по результатам разбора текстового документа выводится в экранную форму в виде графа, вершинами которого являются найденные термины. Связи между вершинами — это ключевые слова. Вершины построенного графа пронумерованы. Перечень терминов с их номерами приведен в таблице, выведенной в экранную форму.
Экранная форма окна "Онтологическая модель, построенная по результатам разбора текстового документа" представлена на рисунке 7.
Разработанное приложение позволяет просматривать одновременно результаты разбора текстового документа и онтологическую модель, построенную по этим результатам.
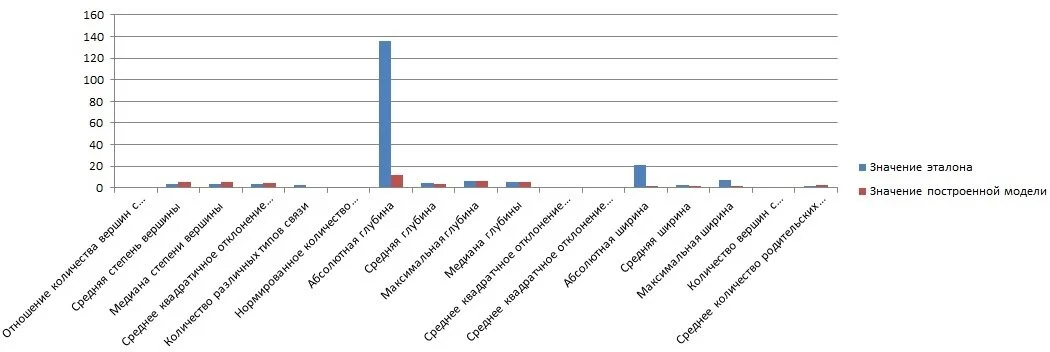
Суть проводимого эксперимента в том, что выполняется сравнительный анализ онтологических моделей, которые строит система и с моделями-эталонами, предоставленными экспертом. Также выполняется расчет метрических характеристик качества как построенных так и эталонных онтологических моделей.
Для выполнения сравнительного анализа использовалась эталонная модель и модель, построенная системой.
Для пары сравниваемых онтологий получены следующие результаты расчета метрик качества онтологических моделей.
Выводы
Проанализировав построенные онтологические модели можно сделать следующие выводы:
- Разработанная система выделяет большее количество вершин, чем эксперт в области построения онтологических моделей;
- Количество всех связей в графе остается приблизительно тем же;
- Значение средней глубины и ширины онтологических моделей уменьшается по сравнению с построенными экспертом;
- Модели, построенные системой более простые по сравнению с построенными экспертом.